Add Structured Testing to Your AI Vibe - with promptfoo

Intro
In my previous promptfoo post, we covered the basics of testing LLM prompts with simple examples using promptfoo. But when you're building an actual application that processes user-generated content at scale, you might discover that your carefully crafted prompt needs to handle far more complexity than you initially anticipated.
Many teams are still doing "vibe testing" - manually checking a few examples, tweaking prompts based on gut feel, and hoping everything works in production. While this might get you started, a systematic evaluation framework puts you significantly ahead of the curve when it comes to building and maintaining reliable AI systems, and provides a mechanism to build a set of repeatable automated regression tests.
Our Assignment
Let's consider an example. You're working with a major ecommerce client, and your team is building a feature that will analyze user submitted product reviews. Your application needs to evaluate the product reviews, classify sentiment, extract key product features mentioned, detect potentially fake reviews, and make moderation decisions. This will help customers find trustworthy reviews and help your business maintain review quality.
The core of this system is a prompt that takes each incoming review and returns structured data, such as sentiment classification, confidence scores, extracted features, fake review indicators, and moderation recommendations.
This prompt might work well during development, but once deployed, it needs to handle the messy reality of real user reviews. Your prompt will definitely need to be able to handle things like:
- Mixed sentiment reviews (loved the product, hated the shipping)
- Fake or suspicious reviews
- Reviews with profanity or inappropriate content
- Sarcastic or nuanced language
- Reviews that mention competitors
This is where a systematic process with multiple scenarios becomes crucial.
Our Requirements
Speaking of systematic processes, before we dive into building our prompt and setting up the prompfoo tests, let's outline what the requirements would look like. We'll use our old friend gherkin.
1Feature: Product Review Analysis Prompt
2
3 Scenario Outline: Prompt analyzes product reviews correctly
4 Given a product review analysis prompt
5 And a "<review_type>" product review
6 When the prompt processes the review
7 Then the sentiment should be classified as "<expected_sentiment>"
8 And fake review indicators should be "<fake_indicators>"
9 And the recommendation should be "<expected_recommendation>"
10 And key features should be extracted
11
12 Examples:
13 | review_type | expected_sentiment | expected_fake_indicators | expected_recommendation |
14 | positive | positive | absent | approve |
15 | negative | negative | absent | approve |
16 | mixed | mixed | absent | flag_for_review |
17 | suspicious | positive | present | flag_for_review |
Gherkin is just a way to describe requirements in plain language. In this case, we have four main test scenarios: positive reviews, negative reviews, mixed sentiment reviews, and suspicious/fake reviews.
Promptfoo doesn't use gherkin, but I do, and it helps me think through the scenarios we need to cover. We'll translate these scenarios into actual promptfoo tests next.
Moving Beyond Inline YAML: File-Based Organization
In my last post we defined the entire test in YAML. Before diving into complex scenarios, let's improve our testing structure by moving prompts into separate files. This makes them easier to maintain, version control, and collaborate on.
Project Structure
1promptfoo-product-reviews/
2├── prompts/
3│ └── analyze-review.txt
4├── test-data/
5│ ├── positive-review.txt
6│ ├── negative-review.txt
7│ ├── mixed-review.txt
8│ └── suspicious-review.txt
9├── analyze-review-spec.yaml
10└── package.json
Creating Our Review Analysis Prompt
Let's first create a prompt specifically designed for ecommerce product review analysis:
prompts/analyze-review.txt
1You are an expert product review analyzer for an ecommerce platform. Analyze the following product review and provide a structured assessment.
2
3Product Review:
4{{review_text}}
5
6Provide your analysis in the following JSON format. Return ONLY the JSON object, no markdown code blocks, no explanations, no additional text:
7{
8 "sentiment": "positive|negative|mixed",
9 "confidence": 0.0-1.0,
10 "key_features_mentioned": ["feature1", "feature2"],
11 "main_complaints": ["complaint1", "complaint2"],
12 "main_praise": ["praise1", "praise2"],
13 "suspected_fake": boolean,
14 "fake_indicators": ["indicator1", "indicator2"],
15 "recommendation": "approve|flag_for_review|reject",
16 "summary": "Brief 1-2 sentence summary"
17}
18
19Focus on:
20- Accurate sentiment classification, especially for mixed reviews
21- Extracting specific product features mentioned
22- Identifying potential fake review indicators such as generic language without specific details, suspicious patterns, overly positive language, and extreme superlatives, overly negative language
23- Providing actionable moderation recommendations
24
25IMPORTANT: Return ONLY valid JSON. Do not wrap in markdown code blocks or add any other text.
Test Scenarios: Real-World Product Reviews
So that's the prompt we're going to test. Now let's create diverse test scenarios that represent what you'd actually encounter in production. You might make these up, or you might use some actual production reviews.
Scenario 1: Genuine Positive Review Example
test-data/positive-review.txt
I've been using these wireless earbuds for 3 months now and I'm really impressed. The battery life is excellent - I get about 6-7 hours of continuous listening, and the case gives me 2-3 full charges. The sound quality is crisp and clear, with good bass response for the price point. They stay comfortable in my ears during workouts and haven't fallen out once. The touch controls take some getting used to but work reliably once you learn them. Only minor complaint is that the case is a bit bulky for my small pockets, but that's a trade-off for the extra battery. Would definitely recommend for anyone looking for reliable wireless earbuds under $100.
Scenario 2: Detailed Negative Review
test-data/negative-review.txt
Very disappointed with these earbuds. The connection constantly drops out, especially when my phone is in my pocket or more than a few feet away. The battery life is nowhere near the advertised 8 hours - I'm lucky to get 4 hours before they die. The sound quality is muddy and lacks clarity, particularly in the mid-range frequencies. They're also uncomfortable for extended wear - my ears start hurting after about an hour. The touch controls are oversensitive and constantly trigger accidentally when I adjust them. For the price, I expected much better quality. I've had $20 earbuds that performed better than these. Returning them and looking for alternatives.
Scenario 3: Mixed Sentiment Review
test-data/mixed-review.txt
These earbuds are a mixed bag. On the positive side, the sound quality is really good - clear highs, decent bass, and good overall balance. The build quality feels solid and they look premium. The battery life meets expectations at around 6 hours. However, there are some significant issues. The Bluetooth connection is unreliable - frequent dropouts and sometimes one earbud stops working randomly. The fit is also problematic for me - they tend to slip out during exercise despite trying all the included ear tips. Customer service was helpful when I contacted them about the connection issues, but the firmware update they suggested didn't solve the problem. Overall, great sound quality let down by connectivity and fit issues. Might work better for others but not ideal for my use case.
Scenario 4: Suspicious/Fake Review
test-data/suspicious-review.txt
Amazing product! These earbuds are the best I have ever used in my entire life. The sound quality is absolutely perfect and the battery life is incredible. They are so comfortable and never fall out. The connection is always stable and strong. I love everything about these earbuds and they exceeded all my expectations. Everyone should buy these right now because they are the greatest earbuds ever made. Five stars without any doubt! Highly recommend to all people who want amazing earbuds with perfect quality and performance.
Comprehensive Test Configuration
Now let's create a promptfoo configuration that tests all these scenarios with appropriate assertions:
analyze-review-spec.yaml
1description: Product Review Analysis Testing
2
3prompts:
4 - file://prompts/analyze-review.txt
5
6providers:
7 - openai:chat:gpt-4o-mini
8
9tests:
10 # Test 1: Genuine Positive Review
11 - vars:
12 review_text: file://test-data/positive-review.txt
13 assert:
14 - type: is-json
15 - type: javascript
16 value: |
17 const response = JSON.parse(output);
18 response.sentiment === 'positive' && response.confidence > 0.7
19 - type: contains-json
20 value:
21 suspected_fake: false
22 - type: llm-rubric
23 value: "Should identify key positive features like battery life, sound quality, and comfort. Should not flag as fake since it contains specific details and minor complaints."
24
25 # Test 2: Detailed Negative Review
26 - vars:
27 review_text: file://test-data/negative-review.txt
28 assert:
29 - type: is-json
30 - type: javascript
31 value: |
32 const response = JSON.parse(output);
33 response.sentiment === 'negative' && response.confidence > 0.7
34 - type: contains-json
35 value:
36 suspected_fake: false
37 - type: llm-rubric
38 value: "Should identify specific complaints about connection, battery, sound quality, and comfort. Should extract main issues for product team review."
39
40 # Test 3: Mixed Sentiment Review
41 - vars:
42 review_text: file://test-data/mixed-review.txt
43 assert:
44 - type: is-json
45 - type: javascript
46 value: |
47 const response = JSON.parse(output);
48 response.sentiment === 'mixed'
49 - type: llm-rubric
50 value: "Should correctly identify mixed sentiment, extracting both positive aspects (sound quality, build) and negative aspects (connectivity, fit). This is the most challenging scenario for sentiment analysis."
51
52 # Test 4: Suspicious/Fake Review
53 - vars:
54 review_text: file://test-data/suspicious-review.txt
55 assert:
56 - type: is-json
57 - type: contains-json
58 value:
59 suspected_fake: true
60 - type: javascript
61 value: |
62 const response = JSON.parse(output);
63 response.fake_indicators && response.fake_indicators.length > 0
64 - type: llm-rubric
65 value: "Should detect fake review indicators: overly positive language, lack of specific details, generic praise, and extreme superlatives."
Understanding the Test Specification
Let's break down what this test configuration accomplishes. We have four distinct tests that correspond to the four key scenarios mentioned above:
- Test 1: Genuine Positive Review - References
positive-review.txt - Test 2: Detailed Negative Review - References
negative-review.txt - Test 3: Mixed Sentiment Review - References
mixed-review.txt - Test 4: Suspicious/Fake Review - References
suspicious-review.txt
Each test loads its respective product review using the file:// syntax, which tells promptfoo to read the content from the specified file and inject it into the review_text variable in our prompt.
Multi-Layered Assertions
Notice that we're using multiple types of assertions for comprehensive validation:
is-json- Ensures the output is valid JSON formatcontains-json- Checks for specific key-value pairs in the responsejavascript- Uses inline JavaScript for custom validation logic (like checking sentiment and confidence scores)llm-rubric- Uses an LLM to evaluate whether the output meets human-readable criteria
The inline JavaScript assertions are particularly powerful for complex validation. For example:
1const response = JSON.parse(output);
2response.sentiment === 'positive' && response.confidence > 0.7
This validates both the sentiment classification AND ensures the AI is confident in its assessment, helping us catch edge cases where the model might be uncertain.
Installation & Setup
1# Install as a dev dependency in your project
2npm install --save-dev promptfoo
Run the test
1# Run the tests
2npx promptfoo eval -c promptfoo-product-reviews/analyze-review-spec.yaml --no-cache
3# View the results in web viewer
4npx promptfoo view -y
Understanding the Results
The web viewer has a lot going on, and I could do an entire walkthrough of its features. For now, let's focus on the key insights it provides into the test and evaluation results.
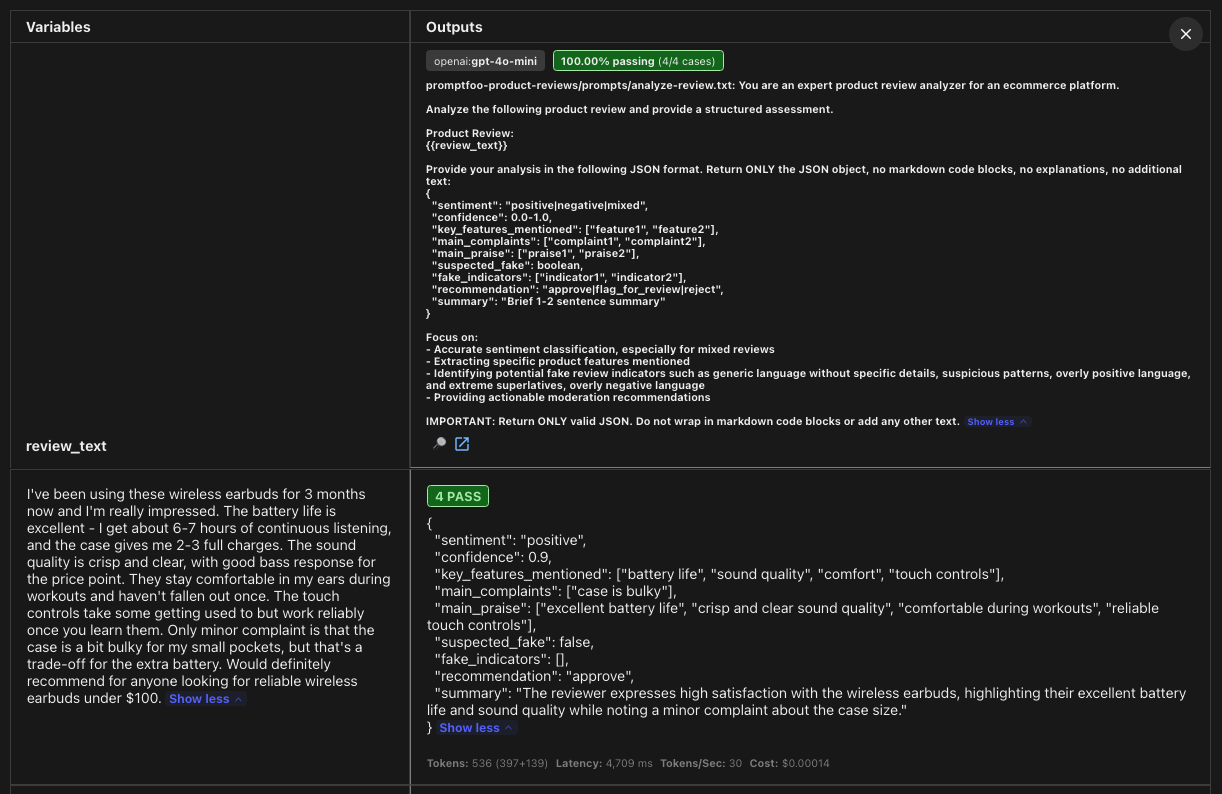
Note the prompt did a pretty good job at analyzing the review based on our requirements, and displays the actual response from the test:
1{
2 "sentiment": "positive",
3 "confidence": 0.9,
4 "key_features_mentioned": ["battery life", "sound quality", "comfort", "touch controls"],
5 "main_complaints": ["case is bulky"],
6 "main_praise": ["excellent battery life", "crisp and clear sound quality", "comfortable during workouts", "reliable touch controls"],
7 "suspected_fake": false,
8 "fake_indicators": [],
9 "recommendation": "approve",
10 "summary": "The reviewer expresses high satisfaction with the wireless earbuds, highlighting their excellent battery life and sound quality while noting a minor complaint about the case size."
11}
Adding the tests to CI
This is a great start, but we can take this a step further. Since promptfoo just runs from the command line, we can include it as a regression test in our CI pipeline and ensure that future prompt changes don't break these tests.
If we make changes to the prompt, or change the LLM provider, we can re-run this test and see if the results change. If they do, we can investigate why.
As requirements change and morph, we can adapt the tests accordingly.
Wrap-up
In this post, we've explored how to set up a comprehensive testing framework for AI-generated product reviews using promptfoo. By defining clear test scenarios and leveraging multi-layered assertions, we can ensure our AI behaves as expected across a range of inputs.
It might not surprise you to learn that my prompt was not perfect the first time. Since I setup my automated tests first, it made it easy to iterate on the prompt development. Sounds like test driven development, huh?
That's it for now. Stay tuned for another promptfoo post before too long!